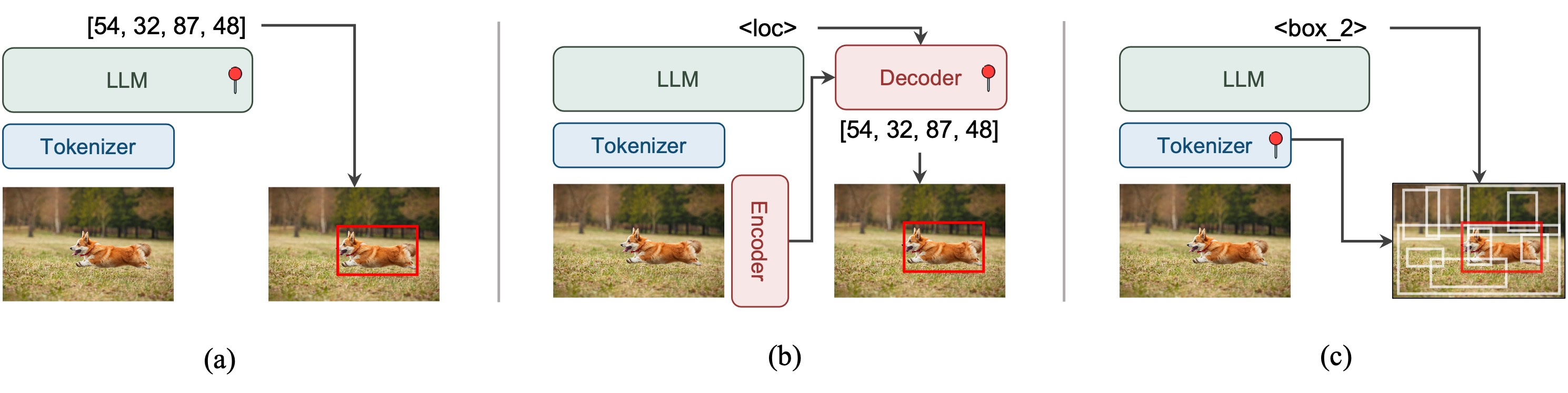
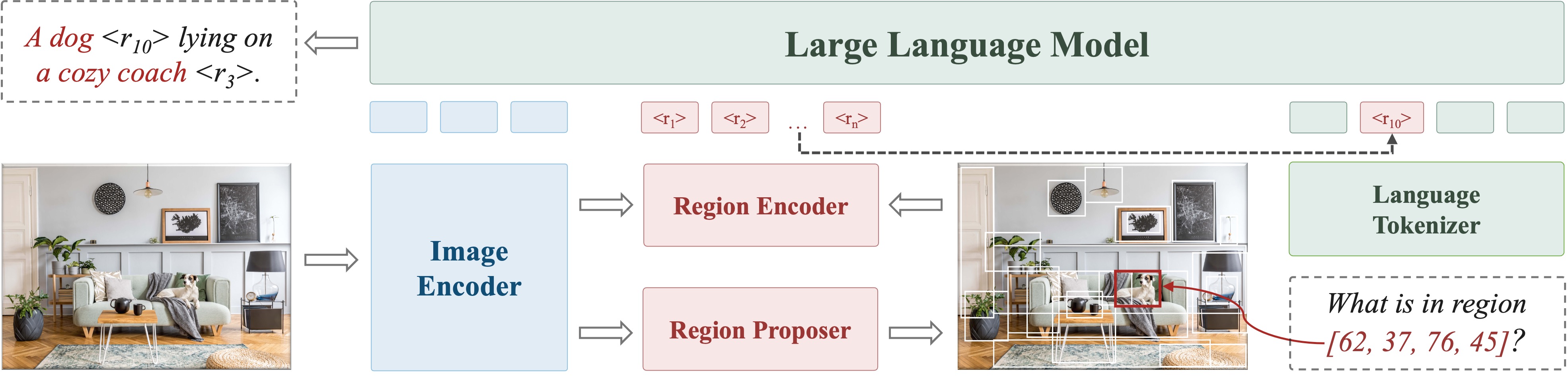
Abstract
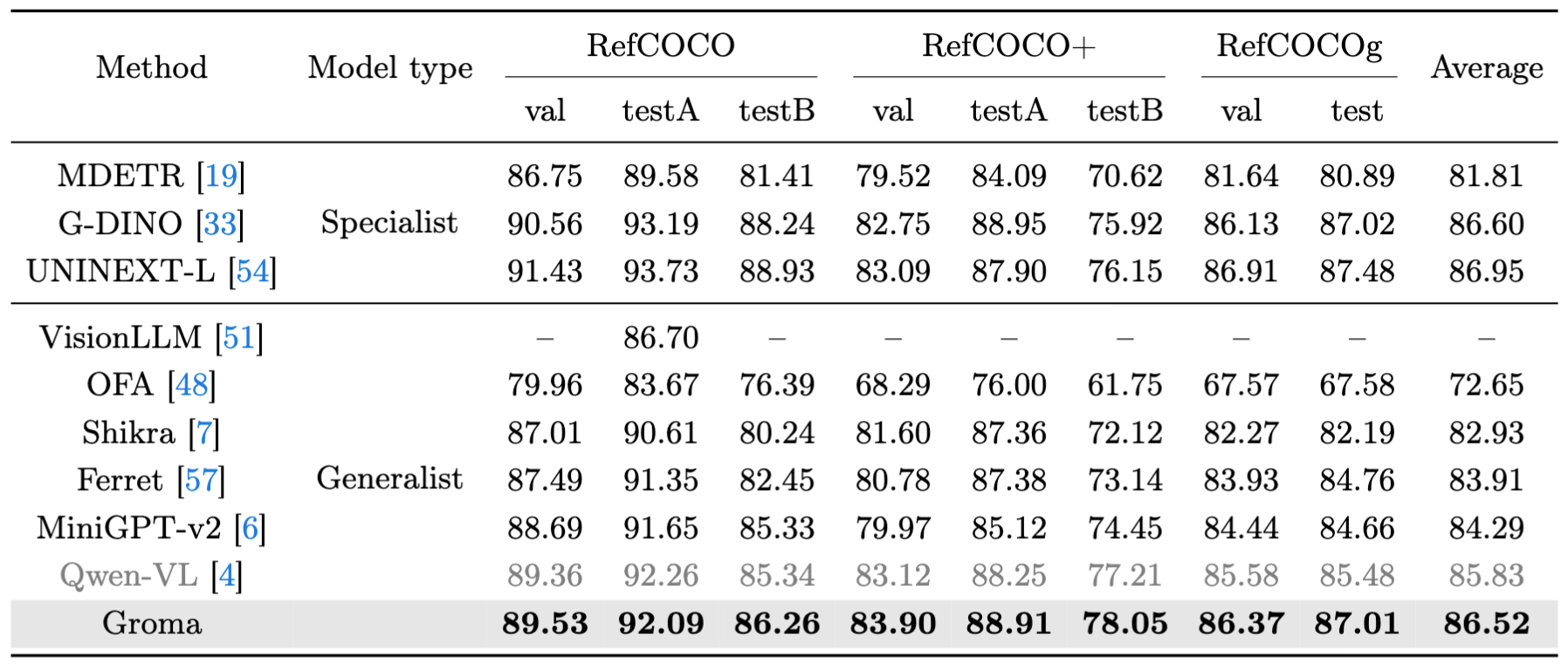
We introduce Groma, a Multimodal Large Language Model (MLLM) with grounded and fine-grained visual perception ability. Beyond holistic image understanding, Groma is adept at region-level tasks such as region captioning and visual grounding. Such capabilities are built upon a localized visual tokenization mechanism, where an image is decomposed into regions of interest and subsequently encoded into region tokens. By integrating region tokens into user instructions and model responses, we seamlessly enable Groma to understand user-specified region inputs and ground its textual output to images. Besides, to enhance the grounded chat ability of Groma, we curate a visually grounded instruction dataset by leveraging the powerful GPT-4V and visual prompting techniques. Compared with MLLMs that rely on the language model or external module for localization, Groma consistently demonstrates superior performances in standard referring and grounding benchmarks, highlighting the advantages of embedding localization into image tokenization.